ZineCore2 Specification

Personal Project
2026
Vertical
Media Type(s)
Credits
Technical Lead & Strategist
- Andrew Marconi
Inspiration & Reference
- xZINECOREx & ZineCat
- Library of Congress (LOC) MARC Standards
- Anchor Archive Subject Thesaurus
A Metadata Ecosystem for Zine Discovery
ZineCore2 is a metadata ecosystem I designed and implemented to address fragmentation in how zines and DIY publications are cataloged, described, and discovered across institutions and grassroots projects. It shows how I move from domain research and strategy into a spec-first architecture and a working backend in a matter of days using an MVP-first, fail-fast approach.
Project highlights
- Deliverables:
- ZineCore2 metadata specification and profiles
- Public-facing site for zinesters and catalogers
- Django/DRF reference API backend (
ZineCore2/server) - Onboarding and reset tooling for rapid iteration
- Stack: Django, Django REST Framework, PostgreSQL, Python/Textual tooling
- Timeline to first working API: ~3-4 days
Trying to Find Zines in a fragmented ecosystem
I came into this space as a zine reader and user: searching for interesting zines and discovering that discoverability is incredibly difficult. Individual, well-regarded zine catalog systems were often offline, unmaintained, or siloed in a way that made them effectively invisible unless you already knew where to look.
Under the hood, zines live in a mix of systems:
- Traditional MARC-based integrated library systems
- Web platforms such as Omeka and similar tools
- Local spreadsheets or ad-hoc databases
- Bespoke cataloging interfaces tailored to one project
Each system uses its own fields, formats, and subject vocabularies. Union catalog efforts exist, but the ecosystem lacked a modern, clearly versioned spec and a reference implementation that institutions and zinesters could adopt without reinventing the wheel.
At the outset, I set three hard constraints for myself:
- It must be understandable by non-catalogers (zinesters, volunteers, small community archives).
- It must integrate cleanly into existing institutional systems and identifier schemes.
- It must be easy to stand up and iterate on, built from mature, open-source technologies.
Spec-first and ecosystem-oriented
Rather than jumping straight into code, I treated this as a standards and information-architecture problem.
Research and framing
For this, I:
- Surveyed existing zine metadata work and cataloging practices.
- Looked at the “languages” different systems speak: MARC, BibTeX, various XML formats, JSON exports, local fields and spreadsheets.
- Studied how existing catalogs and union projects were handling (or struggling with) cross-collection discovery.
This led to a key insight: the problem is not just “build another catalog,” it's design a lingua franca that multiple systems at different levels of technical proficiency can map to without losing what makes zine collections unique.
Core strategic decisions
From that, I made three strategic decisions:
- Profiles, not a monolith
Instead of one giant schema, I designed ZineCore2 as a set of discrete metadata profiles. This allows different actors (a single zinester, a community archive, a research library) to adopt only what they need and grow into more complex usage over time. - Separation of concerns: public site vs spec vs implementation
- A friendly, public-facing site (zinecore.org) aimed at zinesters and catalogers.
- A dedicated specification repository (
ZineCore2/spec) aimed at developers and system integrators. - A reference backend (
ZineCore2/server) that proves the spec is implementable and useful in practice.
- Boring, proven stack for the backend
For the server, I chose Django + Django REST Framework + PostgreSQL. These tools are easy to spin up, widely understood by library IT teams and web developers, and stable enough for long-running services. That let me focus on modeling and workflows instead of framework plumbing.
I also defined a “minimum viable ecosystem”: a spec implementable in multiple environments, a canonical backend to validate it, and room for a future Node/Vue frontend as a sample client.
Designing the ZineCore2 profiles
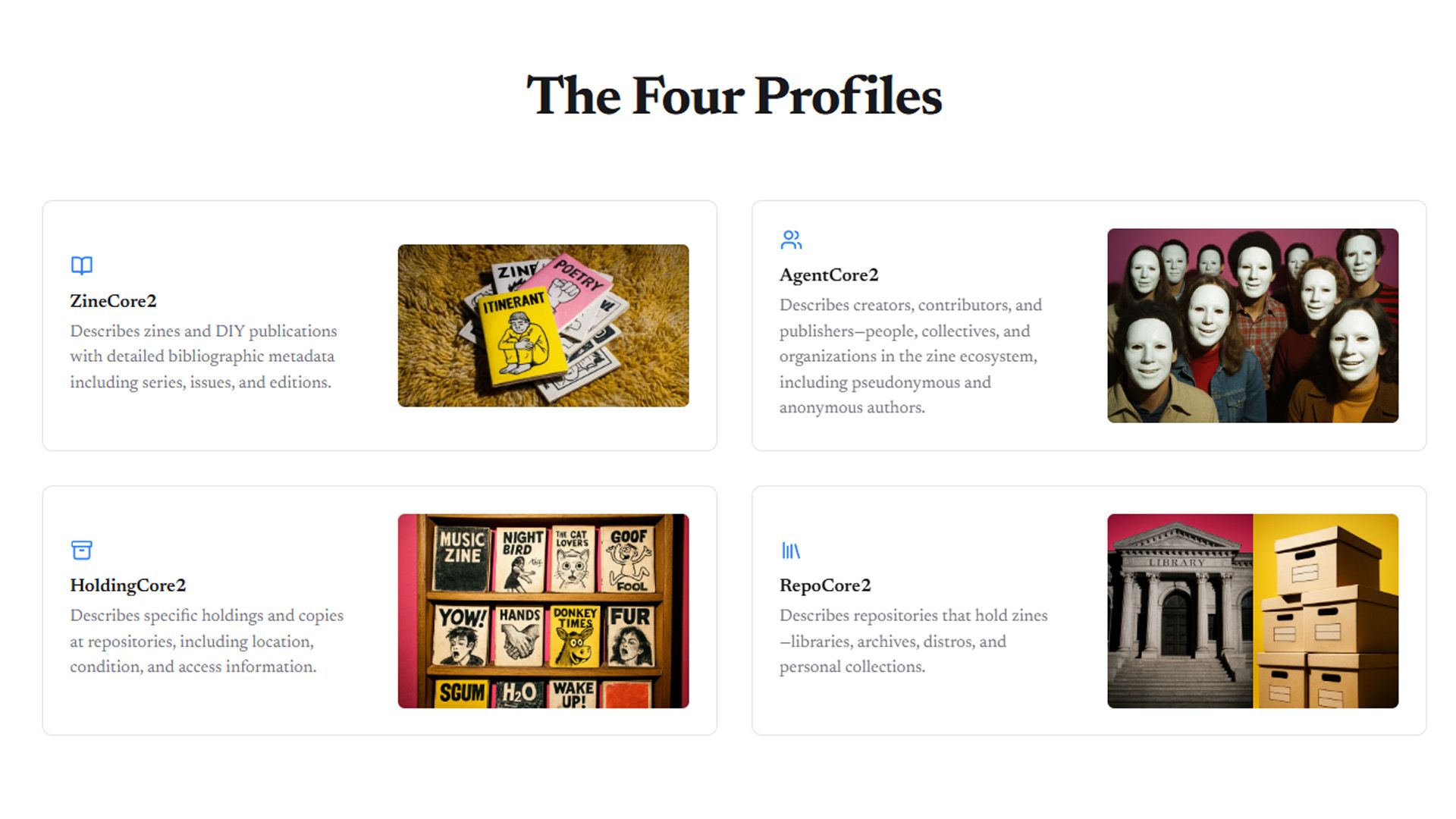
The heart of the project is the design of four core metadata profiles plus a set of controlled vocabularies that normalize description without overwhelming catalogers or zinesters.
Four core profiles
ZineCore2 - Zines and DIY publications
Describes the zines themselves.
- Required fields:
title,creator,subject,genre,date,language,rights - Optional fields: rich relationships, identifiers, notes, and other details for institutions that need more expressive records
Design principle: make it possible to create a valid record in minutes with only a handful of fields, while still supporting deeper description where needed.
AgentCore2 - Creators, contributors, publishers
Represents people and entities associated with zines.
- Required fields:
id,kind,display_name,public - Supports multiple roles (creator, editor, publisher, etc.) and mappings to external identifiers when necessary.
HoldingCore2 - Specific copies at repositories
Models individual copies and where they live.
- Required fields:
id,repository_id,zine_id - Enables union-catalog style queries like “who holds this zine and where?” without exposing internal circulation details.
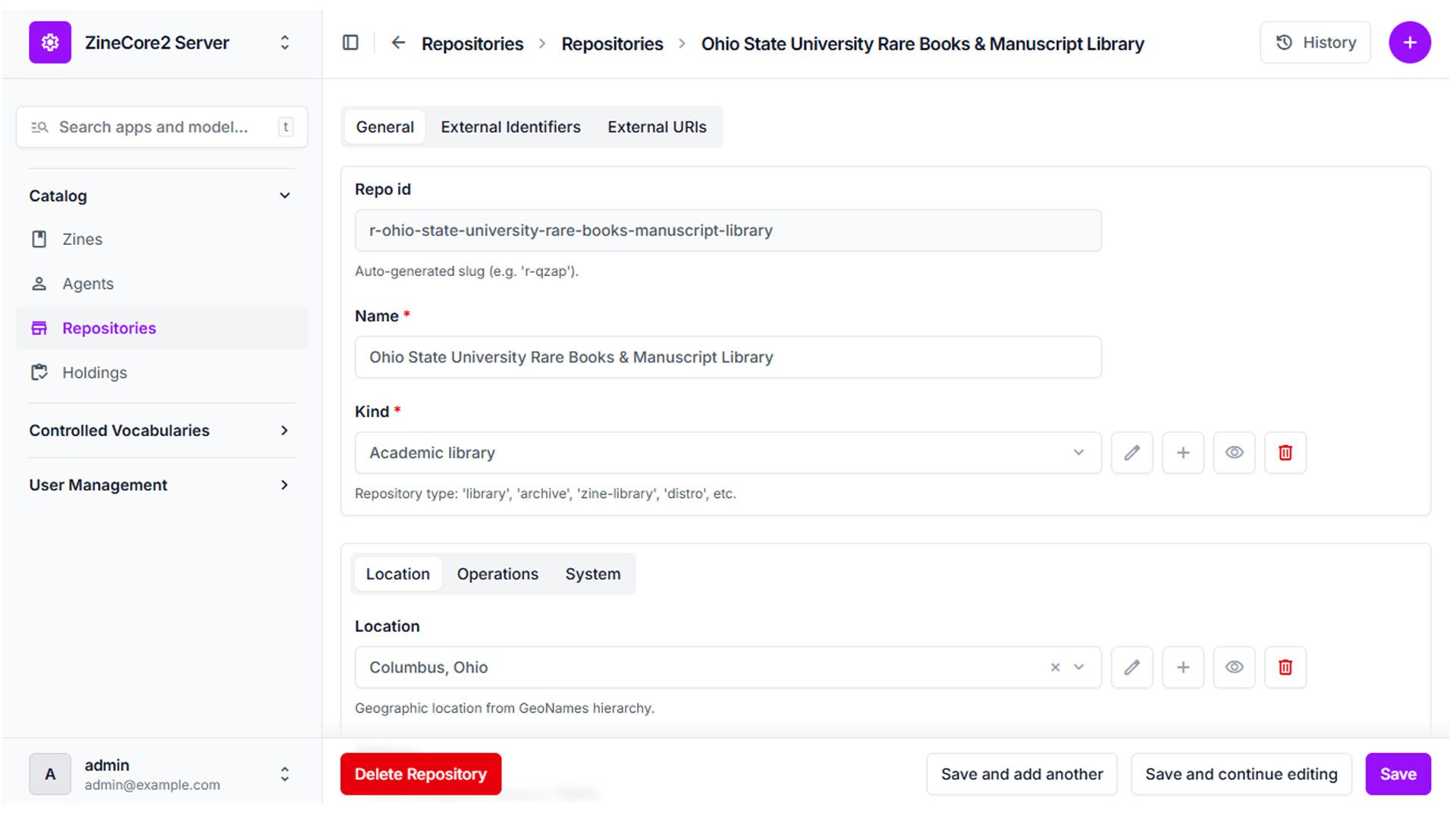
RepoCore2 - Libraries, archives, distros
Describes the organizations and collectives that steward zines.
- Required fields:
id,name,kind,country - Optional fields: mappings to institutional identifiers such as MARC organization codes, ISIL, or ROR IDs.
This allows serious library systems to integrate ZineCore2 with their existing authority files and infrastructure (MARC records and other standards), while keeping the basic profile simple enough for small distros and community archives.
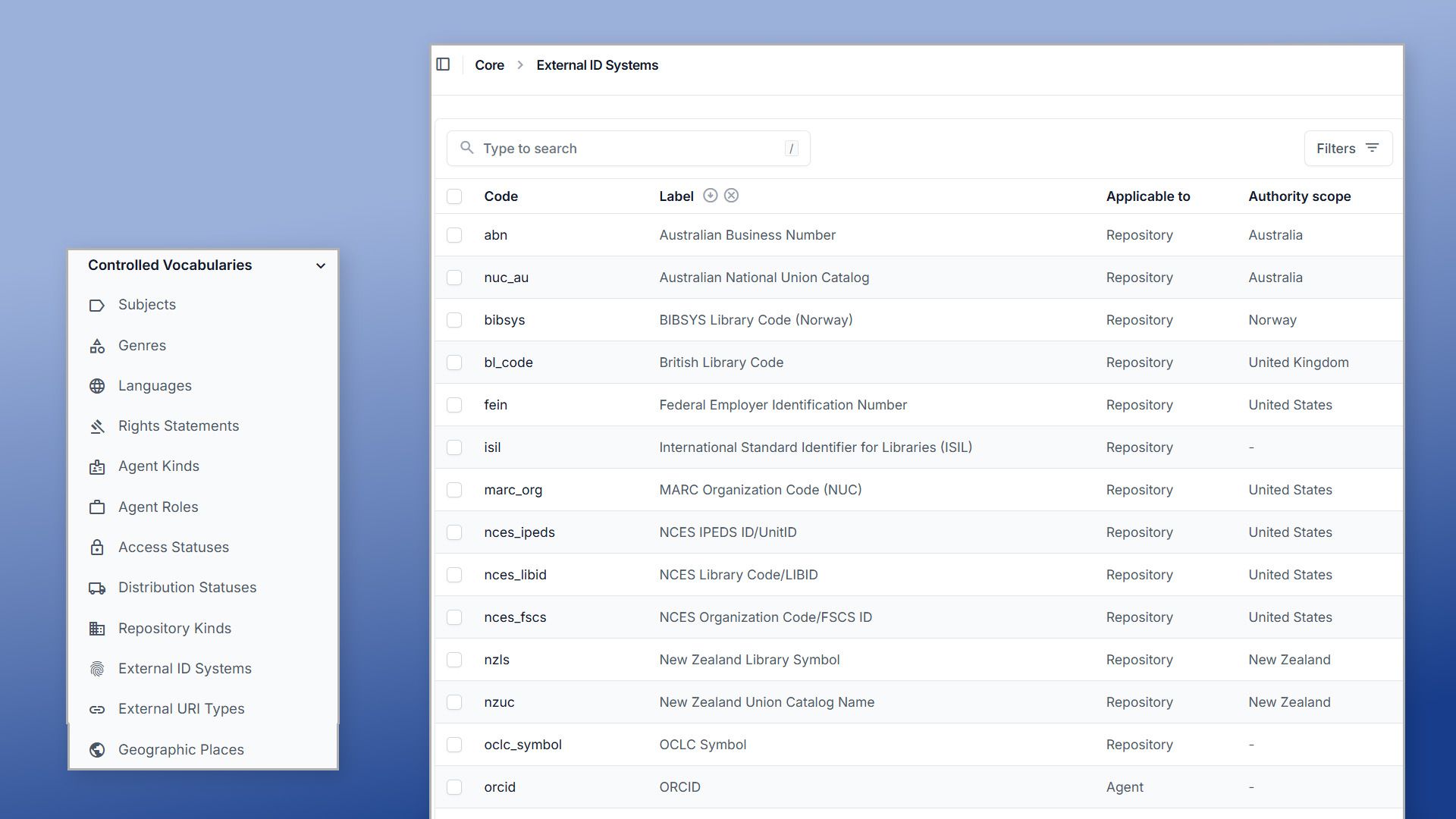
Controlled vocabularies
To reduce chaos without turning the spec into a barrier, I defined controlled vocabularies for:
- Subjects and genres
- Rights statements
- Agent-related values:
agent_kinds,agent_roles - Repository-related values:
repo_kinds - Holding statuses:
holding_access_statuses,holding_distro_statuses - Geographic
locations(using GeoNames - countries and admin1 as the canonical source) andlanguages(using ISO 639-3)
The vocabularies were created based on existing frameworks, specifications and standards. For instance, the subjects and genres are based the already distilled Anchor Archive Subject Thesaurus, which is a Library of Congress indexed source vocabulary for subjects in specific 'zine' topic categories.
A key design tradeoff was limiting the required fields and keeping vocabularies opinionated but not exhaustive. Many fields are optional: irrelevant to some projects, critical to others. Mapping a repository to its MARC, ISIL, or ROR identifiers, for example, is essential for some institutions and noise for others. The profiles are designed so both use cases feel first-class.
Future explorations may be to expand coverage to include this and other sources similar to how The Virtual International Authoritary File (VIAF) and Online Computer Library Center (OCLC) treats mapping disparate systems of metadata so that if one repository uses the Anchor Archive Subject Thesaurus, and another uses the EuroVoc thesaurus, we provide mappings to link similar concepts to aid in discovery.
Audience-aware documentation
I split the documentation by audience:
- zinecore.org is written in friendly language with just enough depth for catalogers, prioritizing clarity over exhaustiveness.
- ZineCore2/spec is aimed at developers, with explicit profile definitions and a structure that mirrors how the backend actually behaves.
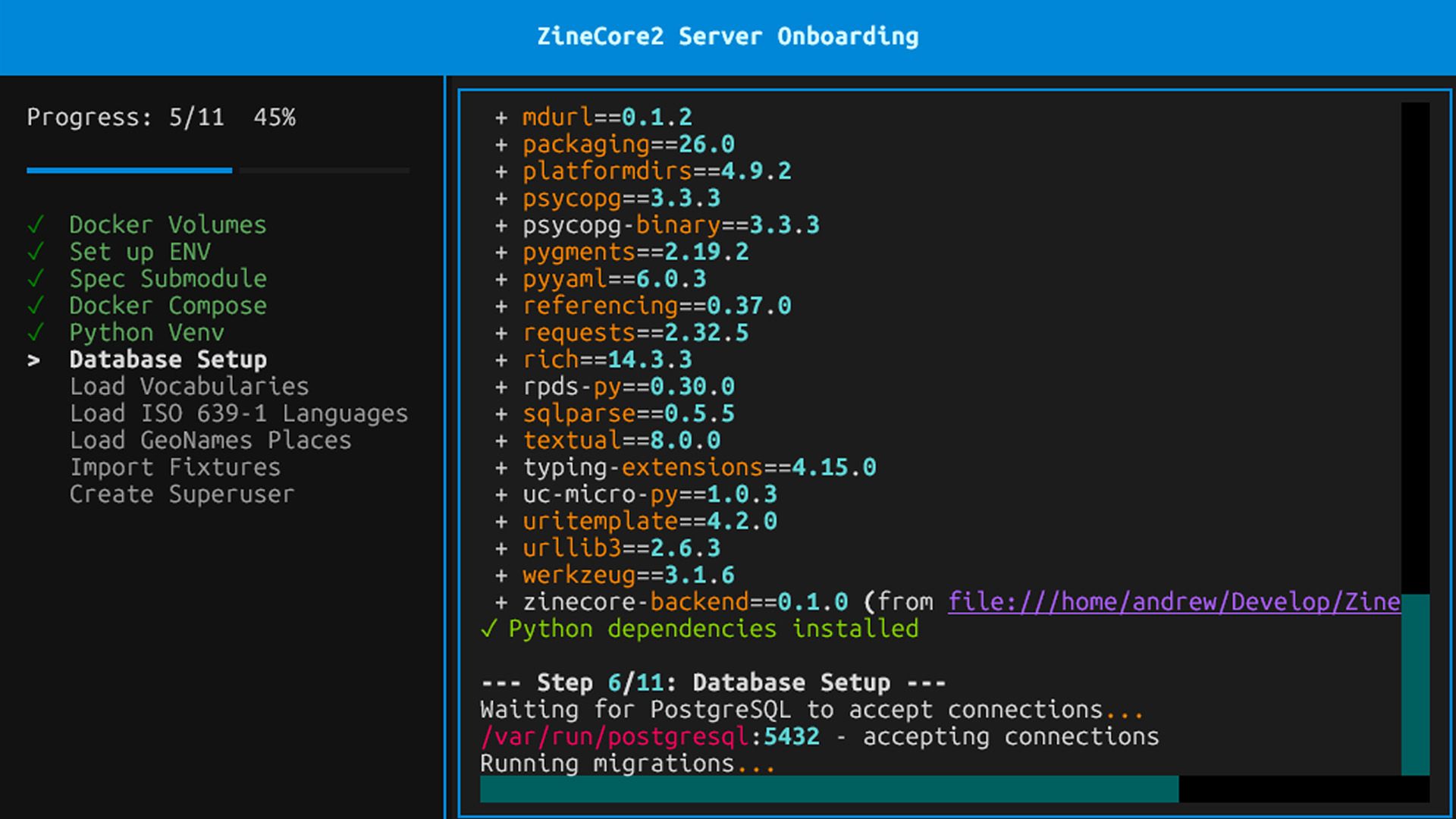
Implementation: a working backend in 3-4 days
With the spec solid enough to test, I moved into implementation, treating ZineCore2/server as both a reference backend and a way to pressure-test the design.
Architecture and tech choices
- Django + Django REST Framework + PostgreSQL
I chose this stack because it's easy to spin up, mature, and widely supported. DRF is effectively the standard for building APIs in Django, and it provides robust serialization, validation, and authentication primitives. Leaning on those allowed me to focus on data modeling and workflows. - Modular, loosely coupled design
I structured the project so each core profile maps to its own cohesive module (zines, agents, holdings, repositories). The components are loosely coupled, making it easier to scale or re-host specific parts in the future (for example, a cloud-based canonical repository service). - Spec-aligned schema
Models, serializers, and API endpoints are tightly aligned with the spec. This keeps documentation and implementation synchronized and makes the server a natural validator for third-party data.
Delivery approach and timeline
I acted as architect, project manager, and technical lead, and used coding agents as implementation helpers where it made sense. My responsibilities included:
- Decomposing the system into well-scoped features aligned with the profiles.
- Defining acceptance criteria, data structures, and validation rules.
- Making architecture, modeling, and integration decisions.
I used an MVP-first, fail-fast strategy:
- Initial target: a working API that can create, retrieve, and list Zines, Agents, Holdings, and Repositories according to the profiles.
- Time to first working, demo-able API: about 3-4 days.
- Iteration: I used the running API to quickly surface missing fields, awkward relationships, or profile ambiguities, then looped those findings back into the spec.
Tooling and developer experience
To make experimentation and adoption smoother, I built supporting tools around the server:
- Onboarding/reset tool (Python + Textual)
A terminal-based tool that automates resetting and configuring the reference implementation. This makes it easy to blow away and rebuild the environment when testing new features, data structures, or migrations. - Import and mapping workflows
I began mapping agents and repositories from different sources into AgentCore2 and RepoCore2. These mappings serve as real-world tests of both the spec and the backend, helping confirm that the profiles accommodate data from multiple “languages” and systems.
Impact and next steps
ZineCore2 is designed as an ecosystem, not just an app:
- A specification that functions as a common metadata language across very different systems and technical capacities.
- A reference backend that proves the spec is implementable and useful, and that can be deployed as a standalone service by institutions or grassroots projects.
- Tooling and architecture that support rapid iteration and future scaling, including a clear path to cloud-hosted or union-catalog scenarios.
In the near term, my focus is on:
- Open-sourcing the
ZineCore2/serverbackend. - Encouraging discussion and collaboration around evolving the standard.
- Exploring a Node + Vue frontend reference implementation to demonstrate how the API can power discovery and staff workflows.
For me professionally, ZineCore2 is a proof-of-concept of how I work:
- Start from real user pain (in this case, my own difficulty discovering zines).
- Do the strategic and IA work to define a realistic standard that respects both institutional and grassroots needs.
- Design an ecosystem (spec, site, backend, tooling) rather than a single artifact.
- Execute quickly with modern tools, MVP-first principles, and an eye toward long-term maintainability.
References
- Website: https://ZineCore.org
- Repository: zinecore2/spec - Dublin Core application profiles, JSON Schemas, JSON-LD contexts, and controlled vocabularies for describing zines, creators, holdings, and repositories.
- Repository: zinecore2/server - Django REST API backend implementing the ZineCore2 metadata profiles with PostgreSQL
- Repository: zinecore2/website - Documentation website for the ZineCore2 metadata specification — built with Nuxt 4 + Docus, hosted at zinecore.org