TTS Compare
Personal Project
2026

Vertical
AI/Machine Learning
Geography
Global
Media Type(s)
CLI Tool
Tags
PythonTTSTextualBenchmarkingGenerative AIOpen Source
Credits
Creator & Developer
Repository
Overview
TTS Compare lets you generate the same input across multiple open-source text-to-speech models in a single run, then compare quality, latency, and per-model feature support side-by-side. The project addresses a recurring practical question, "which TTS should we ship?", by replacing ad-hoc one-off testing with a reproducible harness.
Models covered
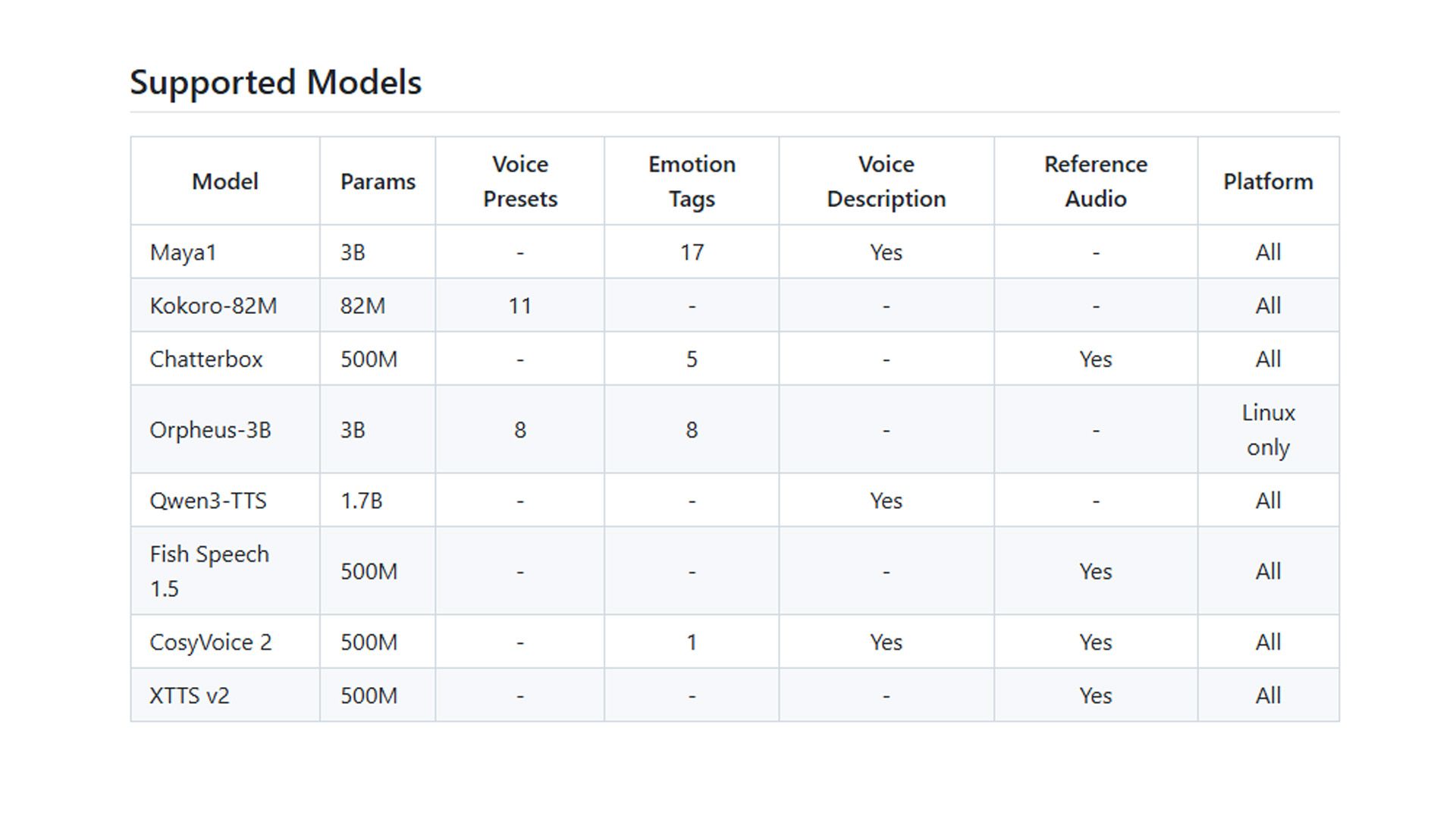
The harness currently runs eight models from across the modern open-source TTS field:
| Model | Params | Notable feature |
|---|---|---|
| Maya1 | 3B | 17 emotion tags, voice description |
| Kokoro-82M | 82M | 11 voice presets, very small |
| Chatterbox | 500M | 5 emotion tags, reference-audio cloning |
| Orpheus-3B | 3B | vLLM backend (Linux only) |
| Qwen3-TTS | 1.7B | Voice description |
| Fish Speech 1.5 | 500M | Reference-audio cloning |
| CosyVoice 2 | 500M | Voice description + reference audio |
| XTTS v2 | 500M | Reference-audio cloning |
Architecture decisions
- Per-model isolated
.venv. Each model gets its own environment undermodels/<name>/to avoid CUDA/torch version skew between systems with conflicting requirements. - JSON-over-stdin worker protocol. Each model is invoked as a subprocess that accepts a JSON request on stdin and writes a WAV file. Decoupling the harness from the model runtimes keeps the Textual TUI snappy and lets a model crash without taking the rest of the run down.
- Hardware adaptive. Detects CUDA, MPS, or CPU and configures models accordingly.
- Three-screen TUI. Input → model selection → execution, with real-time logs streaming as each model generates speech.
References
- Repository: github.com/andrewmarconi/tts-compare